Cloud Native Software is software that gets its configuration information dynamically. TL;DR — Too long; didn’t read Background, Defining Release Management vs Configuration Management. Release Management, This is what we’ve been doing with software since the earliest days of computing. Release management is naming and managing a collection of versioned files. It’s not uncommon for release management systems to pull directly from github with a git sha id or collection of git sha id-s. Named releases of Operating systems and named releases of applications are more examples of software that is under release management. Configuration Management is the information associated with a deployment. The most common examples is IP address and Passwords when an Operating System or application is installed. Another example would be when an email program is configured with your email address and password. Many people will have the same release of the email application, but your configuration should be unique. Cloud Native Computing is the art of deriving as much of the configuration information as possible dynamically. It’s more cloud native when the configuration is generated from other applications. Yes, that means for a given deployment, if there is static configuration information in a text file, git repo, database, etc. it’s less cloud native. When were calling an API to an IAAS platform, were getting the reference to fresh VM, that’s more cloud native. Wrap that API call in to something that composes a pattern of hosts that is fault resistant, that’s even more cloud native. The classic “hello world” written in “C” and in most computer languages since, assume your on a host with no name. That doesn’t work in the cloud because, we have to be able to address the hello world program. Usually through an URL or API. In the name of completeness and to make things more confusing, the need to address a unit of work with out all the tooling associated with making or declaring an URL or API is server-less computing, AKA function as a service (FAAS). An open source implementation of FAAS is OpenWhisk. It allows a hello world like program to exist without IP address or URL information at deployment time. OpenWhisk will deal with the mechanics of addressing and scaling the workload. Linux installed from an ISO will require at least your password information entered in at install time. When Linux is installed from a cloud image, cloud-init will be used for it’s configuration information. This is more cloud native. Current view of the Cloud IAAS, Infrastructure as service, calls an API and gets your VM. This can be done with AWS, CGE, Azure, etc. PAAS, Platform as a Service means services your application will need is already up and running for you to call. If the service in question is implemented and deployed with a cloud native application, It will be implemented with many interchangeable workers, read as fault tolerant. If your calling an API and getting a SQL database, or DNS services implemented with MySql and DNS Bind respectively, your less cloud native and on par with classic hosted solutions. Opensource PAAS projects like Apache Mesos and Cloud Foundry already announced support for Docker. That means PAAS is position to fade or morph in to container as a service (CAAS). These definitions are functionally very useful, but they allow for software to retain classic failure pressure points. Examples include the need to update the kernel of the host your software lives on. Your software may go down for the duration of the patch. A Cloud Native application that gets it’s configuration dynamically means your software can be deployed to a new host, identification to software can be changed to the new host. The result is that your living the cloud dream and enjoying little to no down time with routine operations. Managing the chaos In most cases, your business’s secret sauce will need more than one micro-service. Below are some ways to think about managing the process of decomposing your work load in to some known patterns. Tick Tock pattern of complexity management from Intel is still relevant. Intel managed the complexity of building micro processors with a very simple and elegant discipline of change management by limiting changes to either the chip architecture or die geometry size for every iteration. The benefits were many. Engineers have a clarity of focus. Two different groups of engineers can focus on their craft of architecture and die geometry changes. During implementation engineers had a huge hint on what the source of the problem is based on Tick-Tock cycle. It effectively reduced the potential error space by half. Within Intel, Tick is the die shrink, Tock is architecture change. “Lift and Shift” is the cloud version of Tick, or the die shrink, or deployment on a given infrastructure stack. It doesn’t matter your using configuration management tools like Puppet, Salt Stack, Ansible, or add your favorite configuration management tool. Like any tool, it’s all in the way the user of the tool choose or was forced to use the tool. If were loading up most or all of the data from a static source, it’s more a classic deployment. It doesn’t matter it’s all running on virtual machines on AWS, GCE, Asure, etc. The most Lifted and Shifted application is Word Press, IMHO. Word Press is a Hello World type example for Docker Compose.
Stateless Services
The Cloud Dream is that it should just work. The most straight forward pattern to make a given service more robust is to refactor the service in question in to a stateless API. Implementation will have the API fronted by some type of high available proxy, maybe even implemented by HAProxy. The pattern continues with N copies of a shared nothing controllers. This will allow any given controller to fail and service still work. The next step in the chain may also include many workers behind each of the controllers. Actual implementations of this pattern will vary widely. There are lots of services that already have something very similar. Think Cassandra, etcd, kafka, rabbitmq, the list is too long. Any newer and substantial service will usually require a small team to implement and maintain a given service. Examples of this can be seen in Openstack Nova architecture, Openstack Neutron architecture, other Openstack micro-services combined, Kubernetes architecture, spinnaker, Openwhisk. Apologies in advance to any noteworthy project I neglected to mention. Multiple Micro-services In the past we had longer debug cycles with a monolithic application. Now what we’ve decomposed large applications in to many micro-services, the edge cases of calling these N micro-service, in some given order with a given use case, results with an feature that marketing will call value added services, until the lawyers get involved. Continuous deployments created the Site Reliability Engineer, to be the first point of contact to deal with issues that are expected when integrating multiple micro-services. This shift in where and how the work load for integration of multiple micro-services is done is a very key difference for cloud native software. Continuous deployment of multiple micro-services is so different and so necessary that Mirantis open sourced and dropped it’s baby, the Openstack Fuel installer, bought a software development company, and is now promoting a solution that allows the contiguous deployment of Openstack. Other competing method of deploying openstack includes adopting the use of docker containerized Openstack Components, also known by its project name Kolla. This collection of containers can then be deploy using Ansibile or Kubernetes. There is no clear winner for Openstack deployment pattern. I predict that at some point, all the cloud providers will start adopting Openstack behind the API. It’s just a cost thing that happens when competition starts to squeeze margins. Who are Stakeholders The end user is the first obvious stakeholder. It’s all about making a better experience for the end user. Systems Administrator. I would suggest this is the grand daddy use case. Systems administrators faced with data centers filled with hundreds or thousands of snowflakes built by people who have long left the company. Each computer with applications that look something like a classic LAMP stack. Any routine operational issue like fixing known vulnerabilitys, software updates, power outages, loose cables, even external to the host services like network routing and switching will all cause down time. Data center operators seeking a better way would eventually led to Openstack. I would also suggest that Open Stack was the first famous open source application refactored in to micro services, at least in my tiny view of the big open source world. Openstack is difficult to deploy because each micro-service component with in Openstack was deployed manually. Each Open Stack deployment didn’t necessarily have all components. Each component may have had custom tweaks for their use case. I don’t know who was the first person to use the snow flake analogy to describe an Openstack deployment, but it more accurate than not. We have Rackspace and NASA to thank for starting and releasing Openstack. Site Reliability Engineer, When your web site is a search engine. Your compute load is embarrassingly parallel, you’ll pioneered the use of Site Reliability Engineer to work out issues associated with continuous release, and continuous integration. This is also where the use of Docker shines. By having an immutable image that is run hundreds or thousands of times, were eliminating the risk that any given instance was modified in production. For projects that are less mature and still rapidly changing, This becomes a velocity inhibiting issue. For the uninitiated, embarrassingly parallel computer problems are still very difficult get get right in scale. Rinse and repeat this process enough time as an open source project, you’ll have Kubernetes. These contributions are complements of Google. Application developer productivity focus, In this view your going remove or minimize all barriers that the application developer will encounter to release their code all the way to production. No provisioning requests portals, emails or other gating process for releasing your code. They all do nothing but slow down the edit, compile, run cycles. All applications will be different, so the deployment pipeline must be composable for each micro-servive. There should also be the ability to make any number of new complete deployment copies with meta data to tag a given deployment as development, staging, production or any other of arbitrary states. Then the release of a deployment to production should support canary release pattern, blue green deployment and Chaos Monkey. Not having these strategies in software means the staff will be doing these things with custom in house scripts or even manually where appropriate. The above application concentric features is a description of Spinnaker. Spinnaker is an open source project that was originated by Netflix. Random Thoughts By focusing on your application, the architecture, the tock of the Tick-Tock, your secret sauce, your maximizing your velocity by delegating the “tick” task to a vendor. This does have the external cost of being tied to the next generation of vendor lock in. It’s the same story since the beginning of technology time, first it was the micro processor, then the system, then the operating system, then applications like data storage and databases. All companies endeavor to be a monopoly. Open Source is the new battle ground for vendor lock in. Yes, they all work together, the same way that tight group of girlfriends are all friends. Think friendenemies … The pattern of delegating IAAS to AWS has been very successful for Netflix. Watch any of their You-tube videos on spinnaker, you’ll get testimonials after testimonials of how they use AWS. It’s my opinion that the that most influential contributions to the art and science of cloud computing thus far are Openstack, Kubernetes and Spinnaker, maybe OpenWhisk for an honorable mention. Each of these applications are implemented with many APIs using deployment patterns that enhance fault tolerance. It’s worth mentioning that Openstack started as one large monolithic program. It was refactored in public view in to compute, networking and storage components. Subsequently afterwards many other APIs. Openstack’s list of APIs is still growing today. Google’s Kubernetes is a refactor of an internal deployment tool know by the code name Borg. Netflix’s Spinnaker is a refactor of it’s internal deployment took known by the name Asgard. All of these projects are the result of lots of very talented engineers who worked very hard for many years. If your journey to the cloud has been rocky, your in good company. Cloud native software should get all of it’s configuration information from the cloud. Software must be refactored to accept this pattern. Lift and Shift is not cloud native. It’s a great step in a journey to being fully cloud native. It’s a Tock in the Tick-Tock cycle. In deciding if it’s worth the journey to become fully cloud native, the standard business considerations of cost, benefit, and resources must be decided on a project by project basis. It sounds so simple to pull configuration information for an application dynamically. The actual practice of doing so, as evidenced by Openstack, Kubernetes, and Spinnaker, shows us that it’s difficult to do in practice. At least in the year 2017. This blog post is done with the hopes that your journey to building a cloud native application is a more informed journey.
Virtualized Openstack single node installation with Fuel on Ubuntu KVM
This document contains instructions that will do a install of Openstack all on one host. This is a virtualized install of openstack with Openstack Fuel installer on a vm. Virt-manager is used to configure VMs indvance. Linux bridge and virsh will be used to provide needed networking support. The end result is a KVM host for Fuel, Controller and Compute. The user can then access Fuel UI to configure and install Openstack on vm-s. This blog post install instructions uses a configuration allows Fuel to install with all Fuel defaults. By supporting Fuel defaults, we’re supporting the convention over configuration pattern. This is a natural extension of the Openstack Fuel installer that also has default conventions. Openstack Fuel, one host, these instructions, makes it easy for the first time installers to see all the details of Openstack up and running. This procedure is done on Desktop version Ubuntu 16.04 host. This install strategy will work with all versions of Fuel from Fuel 6 on through Fuel 10.
Starting with Fuel 9, an install will run with one compute. Updates to the various Fuel releases are highly likely to change the required number of controller and compute servers. Your mileage may vary.
Fuel installer is meant to do production installs. The follow on is that if you have enough resources on your host, your able to do an virtualized install with multiple controllers and compute nodes. This will be an easier way to work out your administration strategies, without your companies outages making headline news.
Motivations
The three big benefits for doing a KVM all in one openstack deployment is an increased in vitalization performance, reduced hardware requirements, minimizing difference between development and production.
KVM is an efficient use of resources. Some vendors suggest using VirtualBox for a virtualized install. VirtualBox will run a nested VM with emulation. That means when the compute server starts an new vm instance, it’s running in software emulating hardware for the VM on the compute node. Modern processors have instructions to support running an VM that started a VM on hardware. This feature makes it viable to do useful work with a virtualized openstack install. Based on VirtualBox feature request that has been open for many years, it’s safe to conclude that waiting for VirtualBox to get nested virtualization is not an option. It’s my option that VirtualBox install of openstack stops being useful when the install is complete.
Developing applications on Openstack with out the need for a stack of computers is more efficient. Running a minimal stack of four computers (Fuel, controller, two compute), a switch and some type of NAT device(s) all on physical devices is expensive to purchase, takes lots of space, consumes lots of electricity, requires cooling, and is time consuming to install and operate. This is alot of overhead for a proof of concept or for a one person development environment.
Minimizing the difference between development and deployment reduces errors. “It worked in devstack” but not in production is sometimes a problem.
Configuration needed for default Fuel deployment
The default Fuel network is the network segment that contains 10.20.0.x IP address on VLAN 1. The Fuel documentation reefers to this network as the ‘Admin’ network. I guess it’s full name could be Fuel Administration Network. Fuel Network also assumes that Fuel server is at 10.20.0.2. The Fuel network assumes default gateway is 10.20.0.1. Fuel server performs PXE boot service. In addition, default Fuel install assumes vlan 100 and 101 are used for Storage and Management networks respectively on the same network segment. Regardless of how Fuel is used to do an install, Fuel default assume the network switch, or network bridge, or emulated network segment must support VLAN tagging and un-tagged VLAN packets on the same segment. As a refresher, Ethernet packets without a VLAN tags are defaulted to VLAN 1. Hence, when an node boots up with ‘boot from LAN’ setting selected, it will DHCP boot. Normal default configurations use DHCP packets that are un-tagged. Therefore, defaulted to VLAN 1. Some real world hardware supports setting DHCP boot to happen on a VLAN. Fuel supports putting the Fuel Network on a VLAN also. This feature makes Fuel much more straight forward to install in to an existing network. Conversely, it’s more work and a bit steeper learning curve to setup Fuel in a lab environment.
Default install of Fuel needs Network Address Translation(NAT) of 10.20.0.x and 172.16.0.x networks to the public Internet. This is the default behavior for virsh and virt-manager with 192.168.122.x network. virsh appropriately names the 192.168.122.x network ‘default’. We will leverage virsh and virt-manager to do the NAT and Virtual Machine(VM) management of our nodes. We will call 10.20.0.x and 172.16.0.x networks br1 and br2 respectively.
Secret Sauce
After much digging around the net, it became apparent that KVM, Linux Bridge, virsh, and virtio all work together with vlan tagged frames. The answer turned out to be really easy. vconfig command needs to used to tell a bridge what vlan traffic is allowed on a given bridge. Default behavior of a Linux Bridge is to deny all VLANS. To test this, run the following works in side of a KVM instance.
To get linux bridge to recognize vlan tagged traffic, we need to explicitly tell it what vlan are allowed. This is done with vconfig command ran on the host.
# vconfig add br1 101
br1 will now be able to have untagged traffic and tagged traffic. This enables the Fuel server to use un-tagged traffic for PXE and the tagged traffic for Openstack Management, Openstack Storage and Openstack Neutron controlled tenant networks.
The how to, for installing Fuel in KVM via virt-manager
This is the sequence of steps to get it installed and working. Steps 3, 4, 5, 6 and 7 have more details on how to do each of their respective steps in latter sections.
Install a host computer with Ubuntu 16.04
the user stack is on Ubuntu Host
Host Processor supports virtualization and it’s enabled in the BIOS
for i in 0 1 2 3 do truncate -s 512G /var/lib/libvirt/images/node-$i.img
done
to check file for actual disk usage run:
du -h /var/lib/libvirt/images/node-*
Use virt-manager to create VM
virt-manager is a UI application. That means it needs to be run from the X-Window interface. This blog post used the default Desktop Ubuntu 16.04 install. I’m a big fan of using the command line interface. Creating a small number of VMs, adjusting their configuration, and restarts are just a lot easier with a UI interface. virt-manager is a really good tool to fill this need. Since were in the path of least resistance mode, this installation used the default GNOME 3 shell Unity, by Ubuntu. I just expect the default shell to be less buggy. run virt-manager on the command line. There is no need to run virt-manager as root.
virt-manager
do the following in virt-manager
Configure first node for the fuel
Only one Nic is needed
set network interface to use br1
use a soft allocated file node-0.img for VirtIO Disk
Under “IDE CDROM 1” connect the device to the file download above, typically /home/stack/Downloads/*.iso
Under Boot Options, select IDE CDROM 1 as the Boot device
start the VM
install Fuel with all defaults.
de-select IDE CDROM 1 as the boot device, select only VirtIO Disk 1
reboot VM
Configure nodes 1 through N (at least 2)
each node needs to have two nics. First NIC port is set to br1(with NAT), second NIC port is set to br2(with NAT)
to use a soft allocated file for VirtIO Disk, select one the files created from above $HOME/virt_image/node-?.img
Under Boot Options, select NIC that is on br1, this will enable this vm to pxe boot from fuel server.
Set CPUs, Model: as host-passthrough. Only needed for compute. Needs to be done via virsh on command line
start node
repeat for the desired number of nodes
Using Fuel
Open web browser to 10.20.0.2 The Fuel web page should appear. login as admin password admin
If your in need of a click by click set of instructions for installing Openstack with Fuel, I’ve done that in a previous blog post Ghetto Stack
using the installed openstack from another host
It’s not always convenient to get on the host. Port forwarding can be used to gain access to Fuel server VM. do the following command on the host ubuntu to setup port forwarding to fuel dashboard ( http )
# ssh -L 8443:10.20.0.2:8443 stack@172.19.14.172
in your web browser, put IP address or hostname of your host in the web browser using the port 8443. i.e 192.168.0.100:8443 for keystone
# ssh -L 8000:10.20.0.2:8000 stack@172.19.14.172
for fuel api
# ssh -L 8773:10.20.0.2:8773 stack@172.19.14.172
Remote usage tip
x2go works for remote access to host. It allows for usage of virt-manager without being on the console. In addition, install MATE and XFCE bindings.
Recommended add of br0 tip
Most setups will have network access on the host with a port labeled eth0. If we create a linux bridge and call it br0, attach it to eth0. The host will behave just as it always has. Now when we go in to virt-manager, we can add another Ethernet port to any of our VM and specify br0. After IP address are correctly configured, you can now access the VM from you local network without port forwarding. If you have a VM that’s got a Fuel Default Public IP address, your going to still need to do port forwarding. The follow on is that the Public IP address in the Fuel Environment setup can be changed from the Fuel default range of 172.16.0.x to a range in your eth0 network, Choose br0 as the segment or interface when configuring up a Fuel environment. Then when you allocate a public IP address in Openstack, it will get an IP address in br0 that will be accessible from outside your AIO host.
Memory sizing tip
Nodes consume about 10 gigs of ram just to make it through the install. That means a 32 gig system will be swapping or thrashing when you spin up a VM on a 3 node system . A three node system is a minimal Fuel, one controller, one compute. A 96 Gig of ram system with SSD is a good system.
Notes on Failed Deployment
Fuel is built on Puppet and an orchestration controller. Puppet is built on the concept of idempotent allocation of work to the host. Not a lot of programmatic feedback to catch and deal errors or exceptions. After an arbitrary time out period, and an arbitrary number of retry, Puppet will give up, hence the deployment will fail. If your running an a resource starved machine, Linux will deal with it and just take longer with paging, swapping, etc. Successful deployment is highly dependent on the version of Fuel you choose and your configuration. In simple terms, resourced starved, means slower host, means puppet time outs, means failed deployment. Fuel 6 is the least resource hungry version of Fuel I’ve use. In the event of a failed install, I suggest upping the amount of ram, virtual CPU, using ssds, etc. It will eventually work. Some data points, Dell 720 with 192 gigs of ram, Fuel 9, Two node 64 Gig nodes (one controller and one compute), the Host was consuming all remaining ram, about 40-50 Gigs, for buff/cache. I’ve had successful installs of Fuel 9 on Dell 710 with 96 gigs of ram. Fuel 6 will install on a mac with 16gb ram and virtual box. Each version of Fuel tracks a version of Openstack. As Openstack grows, the installer takes more resources to to run.
Fuel 5 is Openstack Icehouse
Fuel 6 is Openstack Juno
Fuel 7 is Openstack Kilo
Fuel 8 is Openstack Liberity
Fuel 9 is Openstack Mitaka
Fuel 10 is Openstack Newton Fuel 11 is Openstack Ocata Fuel 12 is Openstack Pike – work in progress
Since my last post, I’ve taken a contract job in the bay area. I’ve had an active interest in Openstack since I’ve heard of it in 2011. It’s because I really needed an Openstack like support system when I was running an ISP.
The Ghetto Stack blog post wasn’t a compete serendipitous event. I had a job inquiry from placement firm that there may be another Openstack job opportunity a month prior. As I continued my vacation, I decided it was just time to power up some silicon again, while I sent my resume out twenty times a day. I really wanted to stay in Arizona, that wasn’t in the cards for me.
I’ve relocated to Sunnyvale California. I would expect in the year 2016, In the technology center of the WORLD, I should be able to get gigabit Internet connection to my over priced apartment. Despite proudly proclaiming to be in the heart of Silicon Valley, This city is no better off with regards to connectivity than any other American metropolitan area.
I’ve never fully appreciated all the business forces that affect our lives, until I look time off and went to business school. More than anything else, It was a good time, with good people, and an opportunity to rethink technology without constraints of being an technology person.
A tangible out put from that experience was a way to organize a complex idea in to document that explains how to have cost effective communications competition to every home. Because this idea is seemingly too good to be true, There is an equal and opposite opposing force. Cost effective competition means no one company can ever benefit from a monopoly status. The logical follow on, is that no company will ever want to support this plan. In fact, the Incumbent will viciously fight this plan.
The local cable company here in silicon valley has really bad reviews. I signed up anyway. Same story, more bandwidth, lower cost. I’ll deal with the over worked Comcast employees stuck in a ill-conditioned business that has no chance of survival in a competitive environment. After several bad experiences, on line and over the phone, I canceled it. I found Sonic Internet. I know their struggle well, I had the privilege to lived it. As I wait for my sub-speed DSL to be delivered, I’ve decided to come in the office on a Saturday to get an Internet connection. I’m republishing the post I did in 2009.
I’ve been here many times before. Comcast will shrug off and counter all clams of poor customer service with were big and these are just “isolated incidents”. But, If you believe that they are fat and happy, and just to big and slow to provide competitive service, just maybe, Comcast is vulnerable.
The other force fighting this idea is apathy. What we have is good enough, I’m more interested in other things.
I understand that local city councilmen probably will not fully grok this idea in one read. That means that we the consumers need to motivate a majority of them to understand this, and take the risk of reallocating the cost of deploying fiber to the owners of the streets. Communications is a long lived commodity infrastructure that is as necessary as roads, water, electricity, trash, and sewage. The costs of fiber to the home should be put in the same bucket.
Prior mis-understanding of this idea is that local City Governments will be your Internet Service Provider. City Governments will not be your ISP. Local City Government will do what they do best. They will be the body the oversees ownership of the fiber in the ground and designate some organization to coordinate fair competitive access to the fiber for all interested parties.
I’m told buy Sonic, I’m going to pay $10/month in taxes to the city. Why should I pay that much in taxes for wire in the ground that was placed there before they were born? Say it, extra ordinary profits. If I’m paying $10/month in taxes, I should have fiber to the home! We as consumers should demand fair value for the fees we pay in taxes and to ISPs.
Consumers will only get communications choice when they demand it from their local city governments.
I now reintroduce the Getnet Plan.
Jeffrey Gong — Sat Apr 30 11:42:52 PDT 2016
The Getnet Plan
White Paper
On use of
Passive Coarse Wave Division Multiplexing
For
Promotion of Competition at the Last Mile
January 8, 2009
By
Jeffrey Gong
Overview
Most consumers don’t have fiber optic communications to the home. It is a very expensive and risky investment for more than one or two providers to install fiber optic communications to all addresses. Consumers (and the economy as a whole) benefit when there is broader competition to provide services. A solution is to allocate responsibility for installation and management of communications transport to municipalities using Coarse Wave Division Multiplexing (CWDM) to promote competition between multiple service companies to the same address.
Justification for The Plan
Fiber optic cable is the preferred communications transport. No other transport cable comes close with regards to capacity, distance, and low costs. At some point in the future, fiber optic cable will be installed to every business and home. Consumers will eventually pay for the cost of the network plus a profit for all parties that participate in its operations. Paradoxically, these cables will be in city right of ways (ROW) and we, the taxpayers, own the ROW.s. We as consumers want choices and competition. It makes little sense to have multiple carriers run parallel cables to the same properties. The same fiber will work for cable TV, phone and internet because it can carry multiple services on the same fiber. Fiber optic cables are nothing more than dumb pipes.
A solution that meets the above criteria can be achieved if fiber optic communications transport are installed, owned and managed as a city service. Consumers and service providers would be able to order connections as needed. Cable TV, internet connectivity, and phone services would all be able to use this common transport service at the same time. Installations and maintence will be aligned with other high cost commodity services like roads, water, and sewage.
The following are eight reasons to support this plan. The technology to implement this plan is available now. All we need is the vision and the will to execute this plan.
Reason 1: Now is the Time
Fiber to the home (FTTH) is not widespread.but rapidly becoming so–which allows a decision to be made now avoiding potential regulatory and political issues. Capital expenditure to create a new fiber network to all homes can be made now without significant obstacles if a private entity gets to the table first.
Traditionally, risk-adverse municipalities would want a publicly traded business to bear all of this responsibility. In practice, this could be a potential liability if these companies fail. In bankruptcy, the shareholders will get wiped out, a new buyer will assume the assets in the streets, and the consumers will again pay for the misdeeds of the failing corporation. Separation of these companies from the physical wire in the ground is a natural way to isolate the risk of competitive access carriers. By doing this now before the costs have been incurred to deploy the fiber, our grandchildren will be spared the burden of super normal profits to the owner of the fiber network. There are twisted pair phone wires in the ground that have been generating monthly revenues for the phone company for more than 100 years.
In this communications plan, when a carrier fails, customers could just switch their connection to a new carrier. All the legal issues associated with ownership of wires in the street are gone. All issues associated with a company too critical to fail are gone. Any single service company failure will only affect a portion of the community. Poor service will no longer be rewarded with rate increases. This plan will isolate risks associated with poor management of a communications company. The critical wire infrastructure will no longer be used as leverage to price discriminate.
The full cost of installing fiber to every address has yet to be incurred. It is in the best interest of the community to take the initiative to put a fiber optic network into place. It should be done so in a manner that enables competition. Setup in this way, it can be done in a method that gives ownership to the citizens of the communities it services. It may be managed by the same organization that manages other fixed cost infrastructure like roads and water lines.
Reason 2: Fiber Optical Cable is a Vital City Service
The use of communications has evolved from an optional value added service to become a vital service. A precedent for this recognition may be seen with the Communications Act of 1934 that created the Federal Communications Commission (FCC). The Universal Service Fund was founded to advance the availability of low income, rural, insular and high cost areas at reasonably comparable costs. The Universal Service Fund was funded internally by the Bell monopoly. These actions clearly recognized the importance of communications and put it into law.
Costs for fiber optical cable, CWDM multipliers, and single mode transceiver are all inexpensive commodity products at this time. This is very similar to commodity pricing for the products that are used to construct roads, water, and sewer services. All of these services require access to each home, are capital intensive to install, and have long expected use lifespan. Regardless of the cost of installation, it is a one-time expense. It may be financed and paid back over time like all other city capital expenditures. The match is undeniably similar. We as residents of a city collectively own our roads and water lines. It just makes sense to make the choice to own our fiber as well before costs are incurred.
Investments in fiber optic infrastructure have the same potential to generate revenues for the new owners for decades, if not centuries, into the future. It would be in the best interests of the consumer to let our children own the wires that we will pay to build. In the past, it made sense to let a monopoly own and run a network to deploy an application specific network. The past business case did not allow for alternate uses. Because technology allows multiple generic uses and competition, it makes sense to change policies to reflect current status of technology.
The precedent for enabling a government organization to perform a service on behalf the community is seen in the postal service. Allowing neutral government control of last mile fiber transport is no different. In a time where legislatures struggle with declining tax revenues from phone services, it makes sense to shift the focus from regulation of phone service to regulation of transport on fiber optical cables. We are advocating modern policies to reflect the current state of technology and current needs of the community.
Reason 3: Alignment of Ownership and Management Interests
One of the roles that a city manager will perform is to provide fair use of publicly owned roadways. A competing goal of all private utilities is to gain access to all locations that are economically beneficial for their use. By shifting the responsibility of all communications cabling to the city, we are aligning the use of the street with management of space in public streets.
The .right to exist. in a roadway now becomes a new administrative process that needs to be created and managed. This is another source of administrative overhead that we as taxpayers will bear as increased operational costs for a city management.
If we remove competitive fiber optic carriers from having access to the streets, we will not have to repeatedly tear up the street every time a new fiber optic based services provider wants access to the same road. It makes little sense for city managers to allow roads to be torn up every few years. It makes expensive well-paved road look and drive like test tracks.
In a system where there are multiple fiber optic network owners competing for the same space on the roadway as other services like water, sewage, electrical power, etc., things will go wrong. It is the duty of management to define how these failures are handled. It goes beyond an accidental cut with a backhoe. It can progress into outright theft of someone else.s conduit. If someone sees an unused conduit and they place services in it, we now have to deal with conflicts and potential litigation.
The city owns the streets. They also own water and sewer line in the roads. It is a natural alignment of responsibility to have the city own the fiber in the ground. Improving operational efficiency in city operations and in removing multiple competitive access carriers installing fiber in the street translates into real operational cost savings. These savings will be passed onto the consumers.
Adopting this plan will align the interests of fiber ownership with the interests of management of the streets and management of fiber cable. This plan will have operational efficiency that will be passed on to consumers. Operational efficiency in this case is beneficial because savings come from reduced administrative overhead.
Reason 4: Passive CWDM Technology Enables Plan
Coarse wavelength division multiplexing (CWDM) is a means of combining and/or separating multiple signals of different laser wavelengths into or out of a fiber optic transmission cable in a near passive network. This is exciting because it uses no electrical power to operate.
The alternative today is the use of active electronics. This network does the same job but is significantly more expensive to operate due to its use of power. It uses rack-mountable pieces of electronic equipment that may cost $50,000 per node. The current method of deploying critical communications equipment is to install it with an uninterrupted power supply, air conditioning, and optional back-up power generation. You also need to keep spares parts or service contracts and personnel on staff to operate it all.
Passive CWDM requires almost none of the above. CWDM is a prism that does the same job of combining and splitting different wavelengths onto one fiber. There is no electrical power to operate it. There is no electronic equipment with configuration parameters to set and change. That means there is no engineer to manage it. No need for electricity means there is no need for an uninterrupted power supply, back-up diesel generators, air conditioning, and service contracts to keep it powered and running. It is cheap in comparison to the active alternative.
Each wavelength on a fiber optical cable easily supports current applications. It.s safe to say that the majority of the fiber that is currently deployed is using only one wavelength, most likely 1310-nm. A passive CWDM currently costs a few hundred dollars per unit. I predict that it will get as cheap as a few dollars per unit when they are widely accepted and produced in volume.
Reason 5: Fiber Cable is a Dumb Pipe
Any communications transport medium, twisted pair wire, coaxial, or fiber optic is defined by the equipment on both ends. The actual wire has no intelligence. In ideal cases, the transport requires no power. All of the aforementioned transportation mediums have limits. If the distance to be covered exceeds the respective limits, it must have one or more repeaters to boost the signal. This is the most common need for electrical power. To run data communications over any of the above three mediums, matching equipment on both ends is needed with correct medium adaptors. When this is done correctly, a network connection will be constructed.
Because fiber is just a dumb pipe, it should be treated as such. Since the beginning of communications with wire technologies, companies have earned a price premium with regards to the cost of network deployments because there was no alternate use of the wire. Fiber optic cable is the first transport that can replace all current copper communications. The expected use may now be expanded to include multiple carriers doing the same service.
Dumb pipe means that the cities that assume operations of a fiber network will have a limited range of maintenance requirements. Either the cable will carry a laser or it will fail. If it fails, the operators would use an alternate pair or find the cable break and repair it. This is a task that is well defined. It can be managed on a large scale with government grade employees.
There is no magic in the cable. The magic happens in the equipment on the ends of the pipe. Armed with this knowledge, we should adopt a system where there is cost effective fair access to the cable.
Reason 6: Enables Competition
Laissez-faire works great in a system where goods and services are easily exchanged. Near-monopoly control of systems by telcos and CATV providers does not allow for freer competition. The United States Congress passed the Telecommunications Act of 1996 that forced incumbent local exchange carriers (ILEC) to share existing phone lines with competitors. This act of congress has not created a viable ecosystem of competitive local exchange carriers (CLEC). A fiber optical communications network that allows competition will only happen if we design a publicly owned system to support it.
There are currently 17 defined wavelengths in CWDM with 20nm spacing. Dense wave division multiplexing (DWDM) uses the same spectrum with 2nm spacing. The actual limit of how thin the spacing can be sliced is not known. There is a lot of room for growth. By allowing open market access to these wavelengths to all premises, we will have effectively created a system of market competition with no regards to what type of service that may run on a given wavelength. This is analogous to assigning service providers to different channels on the same fiber.
Single Mode Fiber is the preferred technology to be used in city streets or long haul networks. It has a stated range of 50km (31 miles). Many cable vendors state a range of 70km (43 miles). This means that a single wire center can have all the needed connection in a 30-80 mile diameter go to one location with no need for repeaters. Actual fiber deployments will vary according to specific real estate topography and political considerations.
Networks work best when there is one administrative body for a given network. By allocation of just transport responsibility for the local loop to one organization, we will have the best chance for efficient network deployment, management, and fair competition.
Reason 7: Promotes Innovation
Each wavelength currently can transport 2.5 Gigabits per second for a wavelength. This will yield a 1Gbps bi-directional connection. Single mode gigabit transceivers sell for about $500.00 new. The leading edge of technology is 10Gbps for a frequency is available off the shelf. However, these speeds are not available until FTTH is deployed.
Existing services like cable TV, telephone, and internet all use much less bandwidth than any single wavelength can carry. The goal of having one service organization that can provide TV, phone and Internet is called a triple play. That means there is room for 17 different triple play providers to all homes with fiber.
Because the actual wavelength is mapped from end point to end point, the choice of line protocol is up the consumer and service provider to choose. This open access to the lowest layer combined with the large bandwidths will maximize opportunity for innovations using existing or yet to be invented protocols.
Reason 8: Will Keep the USA Globally Competitive
Like a personality, all countries retain a different global competitive advantage.
The USA has been a market leader in technology. The irony is that a free market economy is at a disadvantage in network construction and operations. Networks are best run and operated by a single organization. By supporting this idea of reallocating responsibility of just the communications transport to neutral party, any nation will become or remain globally competitive.
It is my opinion that the USA must act on this plan to maintain a competitive posture. There are other countries that have nationalized fiber infrastructure to all addresses. This means that the USA is now at a competitive communications disadvantage with these nations. This is done because we continue allow a handful of companies to use their monopoly status to earn super normal profits.
Closing Remarks
There is a lack of fiber optic communication to the home, a lack of real competition of services to the home, and there is significant capital risk for such a project. We have presented a two-step process for solving all three of these issues. The first step is to allocate the responsibility to build a fiber network to local cities that already have experience in exposure to these risk factors. The second step is to use CWDM to allow multiple competing companies parallel access to the same address.
Historically proven importance of communications is impressive. Looking forward, expanded use of communications may be an alternative to travel. This is important given the current awareness of personal carbon footprints. Other benefits include creating a communications system that keeps our country globally competitive.
Install of Openstack with Fuel, Dell R710 and Cisco catalyst 3548. Originally done with fuel 7. This install will work with fuel 7 through 10
Summary
Hardware used in this article is outdated by today’s standards. In addition, the networking is a minimal stick something in place to make it just work. This exact configuration is meant to demonstrate what is a minimal networking needed to make an install work. Hence the Ghetto Stack theme. This is meant to be a reference. Since this post was done, I’ve been able to replicate this pattern to use Fuel to install Openstack all in one host.
The goal is to use Fuel 7.0 defaults as much as possible. This is a write up about what happened when doing an Openstack deployment to physical hosts. This is a convention over configuration approach. This configuration will work with Fuel 6, 7, 8 and 9.
Dell R710 servers are obtainable in used condition at a relatively cheap price. The suggested target price is about $250 each at this time. Each server should be a working configuration that has 2 x quad core CPU, Memory, and Hard drives, DVD, and two power supplies. Prior generation servers are being recycled. For servers in this price range, operational costs like shipping, electrical, labor and other operational costs will exceed the value of the hardware. This once again contributes to the Ghetto Stack theme.
This configuration requires a managed Ethernet switch. Individual ports of the switch need to be configured for different networks. A used 3548 was brought back from its retirement in a garage for this project.
We use commodity NAT routers to provide Internet accessible IP address. This is a simple, easily understandable, and cheap way to achieve this task. It also maintains the keep-it-simple, ghetto theme. There will be a total of three instances where we apply NAT in Ghetto Stack.
This NAT router configuration does not allow traffic from one private segment to other private segments. To work around this, the workstation used to configure, test, and run Openstack is configured to have an IP address in three different network segments.
Reading this document will provide the reader with an understanding of how to configure a network to host OpenStack on physical hosts. Openstack is written in Python, and most Python code acknowledges a convention over configuration approach. That means there are some reasonable defaults chosen. The Openstack community has chosen to have a very minimal number of defaults. Fuel installer goes father and has chosen enough defaults to make Openstack actually work. This setup will work for Openstack Fuel 8 and Fuel 9.
All the host systems used in this setup had two, four core processors, 24 gigs of ram. Network connection was 100 MB switch. The install ran to completion, but the resulting stack has issues. The Fuel all in one host install and runs with a 96 GB ram host. About 20-30 Gigs of ram is consumed for paging and caching. It’s my opinion it’s not the best use of time to do a multi host install of Openstack with each node less than 64 Gigs of ram.
Design Description
IP Network Description
Home Network is the first NAT routing device entering the metaphorical building. It’s the gateway to our Internet provider. In this example, its IP address will be 192.168.0.1/24. We will construct a Openstack deployment that will leave this network in place. In this case, altering this network will cause too much support work. This segment will be isolated by assigning it to VLAN 2.
Fuel Network will be built on 10.20.0.0/24 address space. Default IP address for the Fuel server is 10.20.0.2/24. The Fuel server does it’s own DHCP, BOOTP, and DNS for this network. It also assumes this address space is internet accessible. Default fuel setup assumes that there will be VLAN (802.1Q) encapsulated packets on the same segment. That means we will assign 10.20.0.0/24 to VLAN 1. Switch ports will be configured with “switchport trunk encapsulation dot1q”. The magic of this configuration is that un-tagged packets will be put on VLAN 1. DHCP and BOOTP will use this feature. Tagged traffic will also be switched to the correct ports. It’s assumed that 10.20.0.0/24 has Internet access. This configuration used the sole desktop Workstation for this task. If you want Openstack to stay running while the desktop is being rebooted, use another NAT router instead of the workstation. It’s OK to think it, Ghetto Stack!
Public Network is on 176.16.0.0/24. by default. Fuel expects this to be on a separate interface, on each Openstack node host. Traffic is not VLAN tagged by default. The Ethernet switch port connecting to the public port on each host was connected to switch with the port tagged to VLAN 100. Cisco Lan environment calls this VLAN Native. The packets coming from each of the nodes is not VLAN Tagged. To map this to our setup, each port connected to the nodes has the configuration of “switchport access VLAN 100”. It was only done this way because VLAN tagging is not selected by default on the configuration screen. Again, this is the only other segment that needs to have an Internet accessible IP address. Another commodity NAT router may be used here. In a production deployment, we would use IP addresses assigned by our network administrator or ISP.
Management Network and Storage Network are by default out on VLAN 101 with 192.168.1.0/24 and vlan 102 with 192.168.1.0/24 respectively. Through the magic of a correctly configured VLAN, these networks work.
Network Diagram
VLAN Network Description
VLAN 1 – default, fuel DHCP, all eth0 from servers
VLAN 2 – existing Home Network
VLAN 100 – Public IP address.
All other VLAN just magically work
Switch Configuration.
set password and enable password
set IP address of switch to 10.20.0.254/24
put ports 1 through 8 on VLAN 2
put ports 9 through 32 on VLAN 1. port configured to “switchport trunk encapsulation dot1q”
put ports 33 through 48 on VLAN 100
save configuration
Physical Network Description – Ethernet wiring
Fuel Server
eth0 on to VLAN 1 (switch port 9)
All Openstack nodes
eth0 on any switch port 10 through 32, defaults VLAN 1
eth1 on any switch port 10 through 32, Not required Option
eth2 on any switch ports 33 through 48, tagged to VLAN 100
eth3 on any switch ports 2 through 8, IPMI and Home Network DHCP IP address for debugging
NAT Router 2
Public, or Wide Area side connected to VLAN 2
LAN or Private side connect to VLAN 100
Set IP address range to 176.16.0.1/24, no DHCP
Desktop Workstation – Ubuntu host, NAT Router
eth0 connected to Home Network. If you connect it to a VLAN 2 port, you will have to move your Ethernet wire if you choose to shutdown the switch.
eth1 connected to a port on VLAN 1. IP Address set to 10.20.0.1/24
Use the following commands to provide NAT translations for 10.20.0.0/24 network.
If you want Openstack to run while your desktop is being rebooted, use another NAT router instead of your workstation. Make NAT Router 10.20.0.1, no DHCP. I would suggest that the Workstation should use 10.20.0.254/24 as an IP address in this case.
eth1.100 127.16.0.128/24
this is VLAN tagged. Allows access 127.16.0.0/24 for validating this subnet. IP Address not used by default by Fuel.
There will be may variations for Workstation Network configuration. In the event you only have one ethernet port, consider using VLAN tagged interfaces for any or all of the networks.
Putting it to Together
Powering on the stack.
Standard disclaimer requires me to say, if you have to ask, you need to consult an electrician.
With that said, I couldn’t find my amp meter until after I bought a new one. Uggh… Most modern homes in the USA have 120 V outlets available in the home. It would be common to find 14 gauge wires with 15 AMP breakers. If you have this setup, it doesn’t mean you can draw a full sustained 15 amps through this circuit indefinitely. You should target half that amount. If you go above that do so at your own risk. You should have a goal of never having the circuit breaker kick off the power.
Initial setup, one Dell 2950, seven Dell R170 nodes, one 3548 switch, and one monitor. All plugged into a Tripp-Lite iso bar power strip with a 15 amp circuit breaker. T amp meter showed 12.1 amps immediately after being powered on. Running all the servers at the same time for a few hours kicked the 15 amp circuit breaker in the power strip. I have not run all the servers through one breaker since this time.
Network configuration of Ubuntu 14.04 workstation Below is an interface file from desktop. By connecting one Ethernet port to the Home Network, and the other for Fuel deployment, the workstation will work as expected with Ghetto Stack powered off.
# interfaces(5) file used by ifup(8) and ifdown(8) auto lo iface lo inet loopback
In order to get in through the console, I obtained a USB to serial cable and connected it to my workstation. I already owned a console cable. Connect the serial cable to the console cable, then the console cable to the switch.
Getting in to console
Next, do the following to connect to the switch:
sudo apt-get install cu sudo chmod 666 /dev/ttyUSB0 sudo cu -l /dev/ttyUSB0 -s 9600
c3548#conf t Enter configuration commands, one per line. End with CNTL/Z. c3548(config)#end c3548#
saving configuration
wr mem
undoing a configuration, just put a “no” in front of the line you wish to delete. Use the following session as an example.
c3548#show running-config interface FastEthernet0/33 Building configuration...
Current configuration: ! interface FastEthernet0/33 switchport access vlan 100 end
c3548#conf t Enter configuration commands, one per line. End with CNTL/Z. c3548(config)#interface FastEthernet0/33 c3548(config-if)#no switchport access vlan 100 c3548(config-if)#end c3548#show running-config interface FastEthernet0/33 Building configuration...
Current configuration: ! interface FastEthernet0/33 end
c3548#
Set the secret password. Use the following session as an example.
c3548#conf t Enter configuration commands, one per line. End with CNTL/Z. c3548config)#enable secret changeme c3548(config)#end
Set the line password and secret password. If you don’t, you are not able to telnet in and make changes. Change the “line vty” passwords
line vty 0 4 password YOURPASSWORD login line vty 5 15 password YOURPASSWORD login
Below is the configuration used.
interface FastEthernet0/1 was used to connect to another switch. There is no need to sit in the same room with noisy fans.
interface VLAN1 is set to 10.20.0.254, this is the IP address we can telnet to the switch.
enter, down arrow to Quit Setup, enter, right arrow, down arrow to Save and Quit, enter
It will now complete the install. The root password will also work for all nodes. Fuel sever installs ssh keys on all installed nodes. From fuel server, you can ssh node-x, i.e. ssh node-1.
There is an alert message that takes you to the flowing url, then to the next url to do an update. We are just going to do the update now.
we new have an Environment with nothing configured. The Fuel server is ready. Now power on the nodes.
Configure Each Node
Go in to the bios by pressing F2 during boot, set eth0 to pxe boot as the first item in boot sequence. Fuel server will remember if a host has already been installed, and tell it to boot off of it's hard drive if so. Reboot server. It will pxe boot. It will take several minutes.
Upper right of this screen shows 6 over a 6. The top number is the number of hosts not allocated, and the bottom number shows total hosts. The bell with Red 6 provides more details.
click on Add nodes
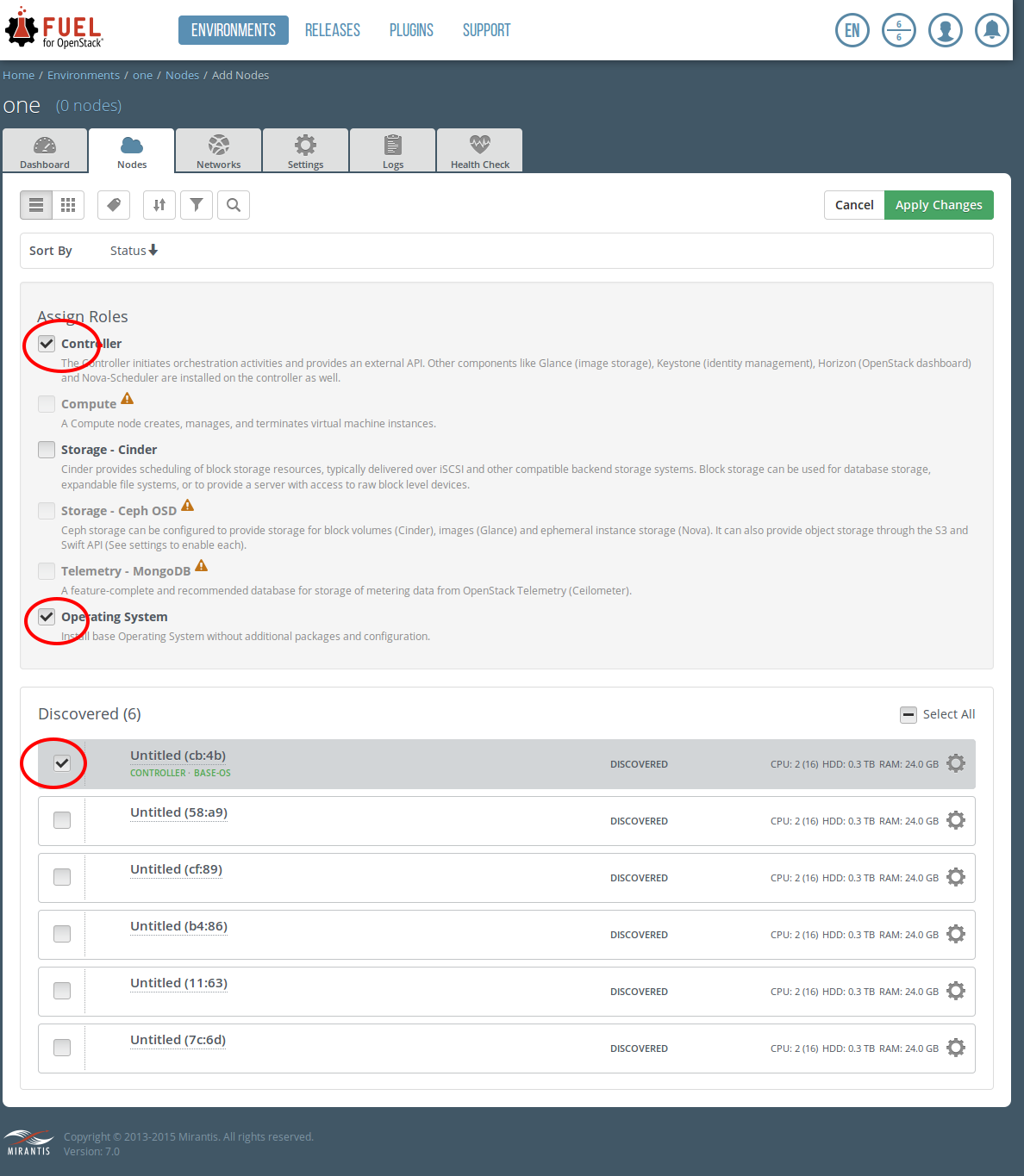
select controller, Operating system, one available node, click Apply Changes
click Add Nodes
select Compute, Storage, Operating System, Select All, click Apply Changes
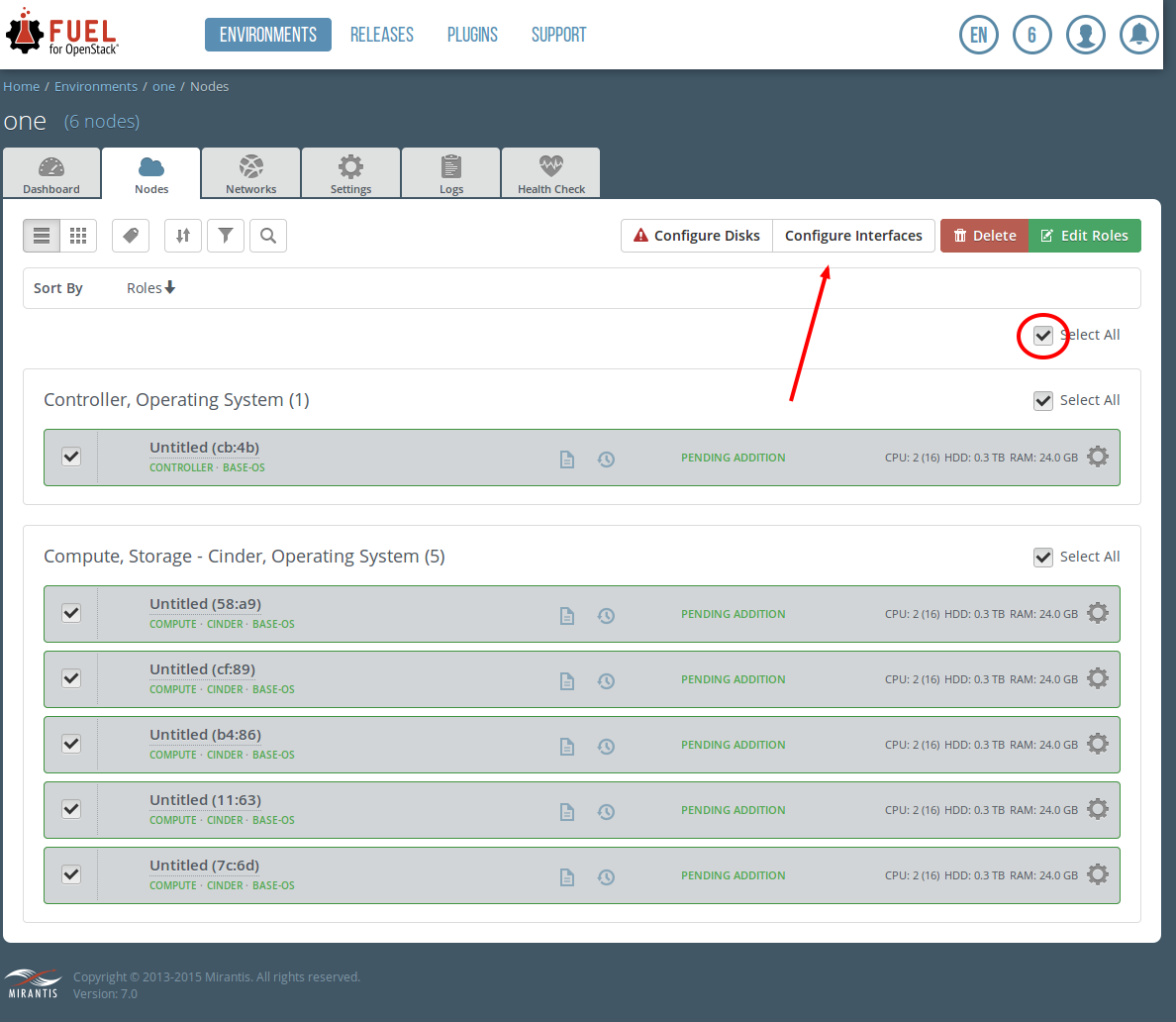
select, Select All, click Configure Interfaces
Left click on Public, Drag and Drop on to eth2 Left click on Storage, Drag and Drop on eth1 Left click on Private, Drag and Drop on eth1 Click on Apply Refresh the page
Click on Networks Tab
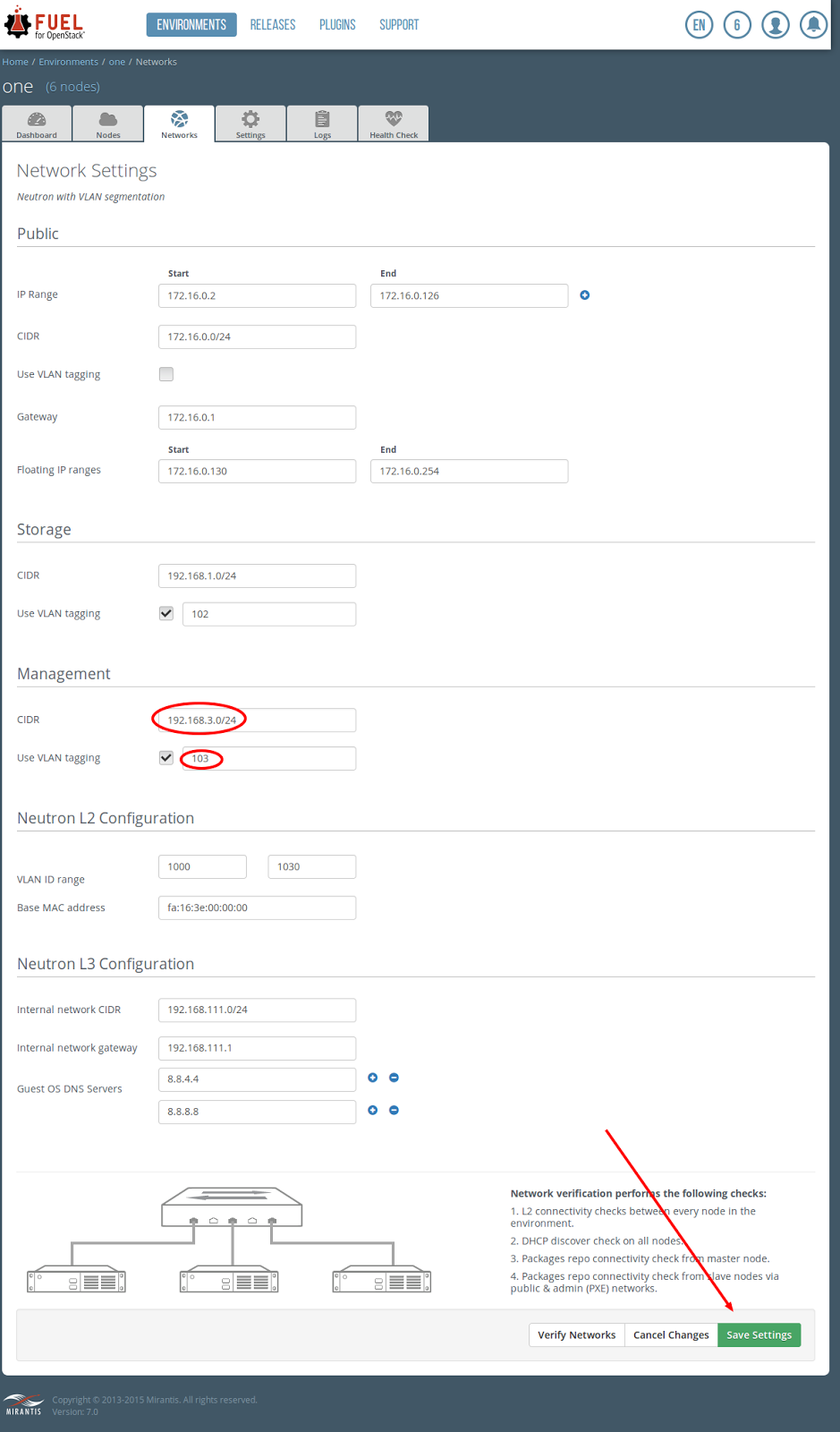
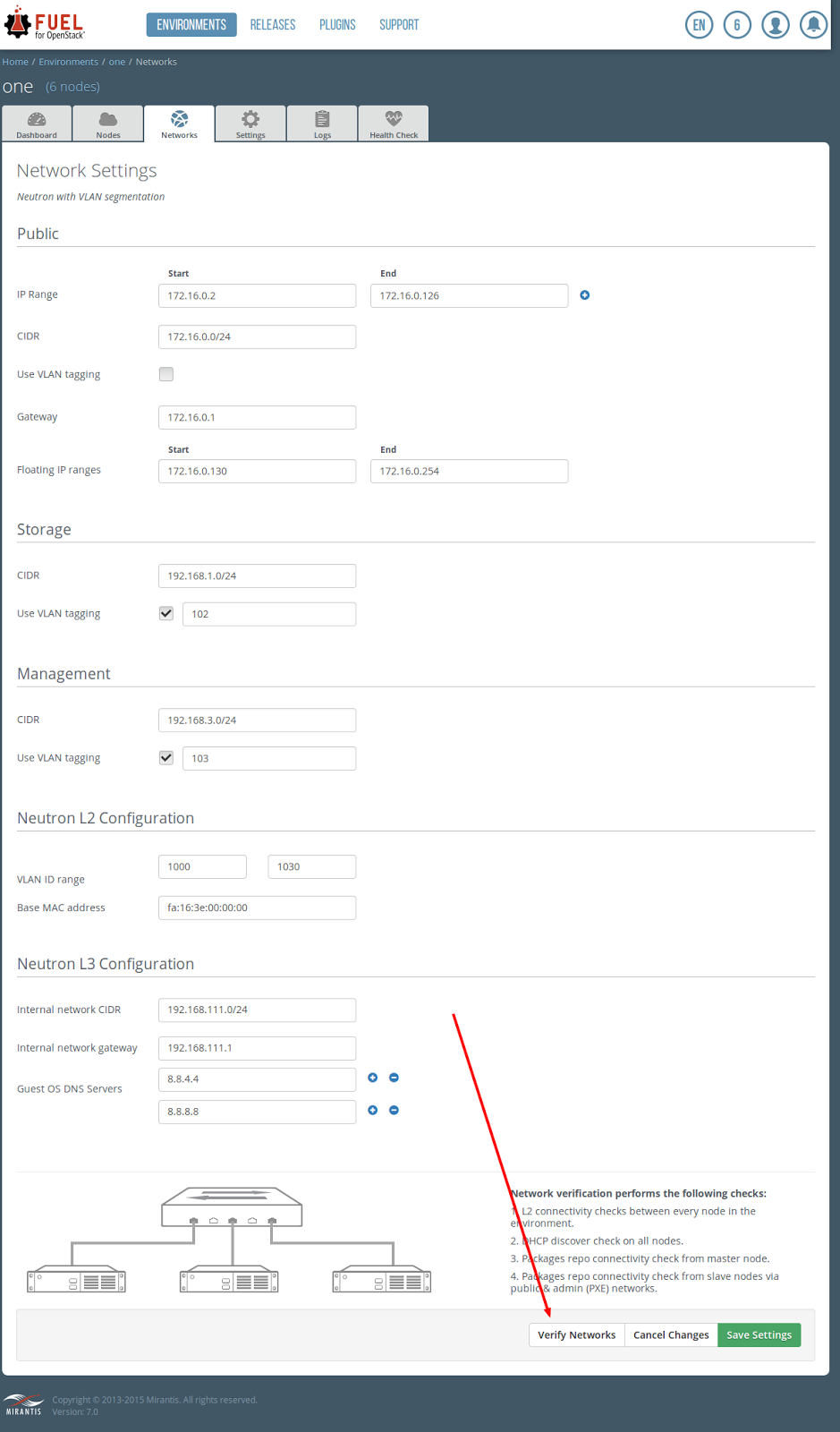
Under the Management section, change CIDR to 192.168.3.0/24 change VLAN tagging to 103 click on Save Settings
click on Verify Networks
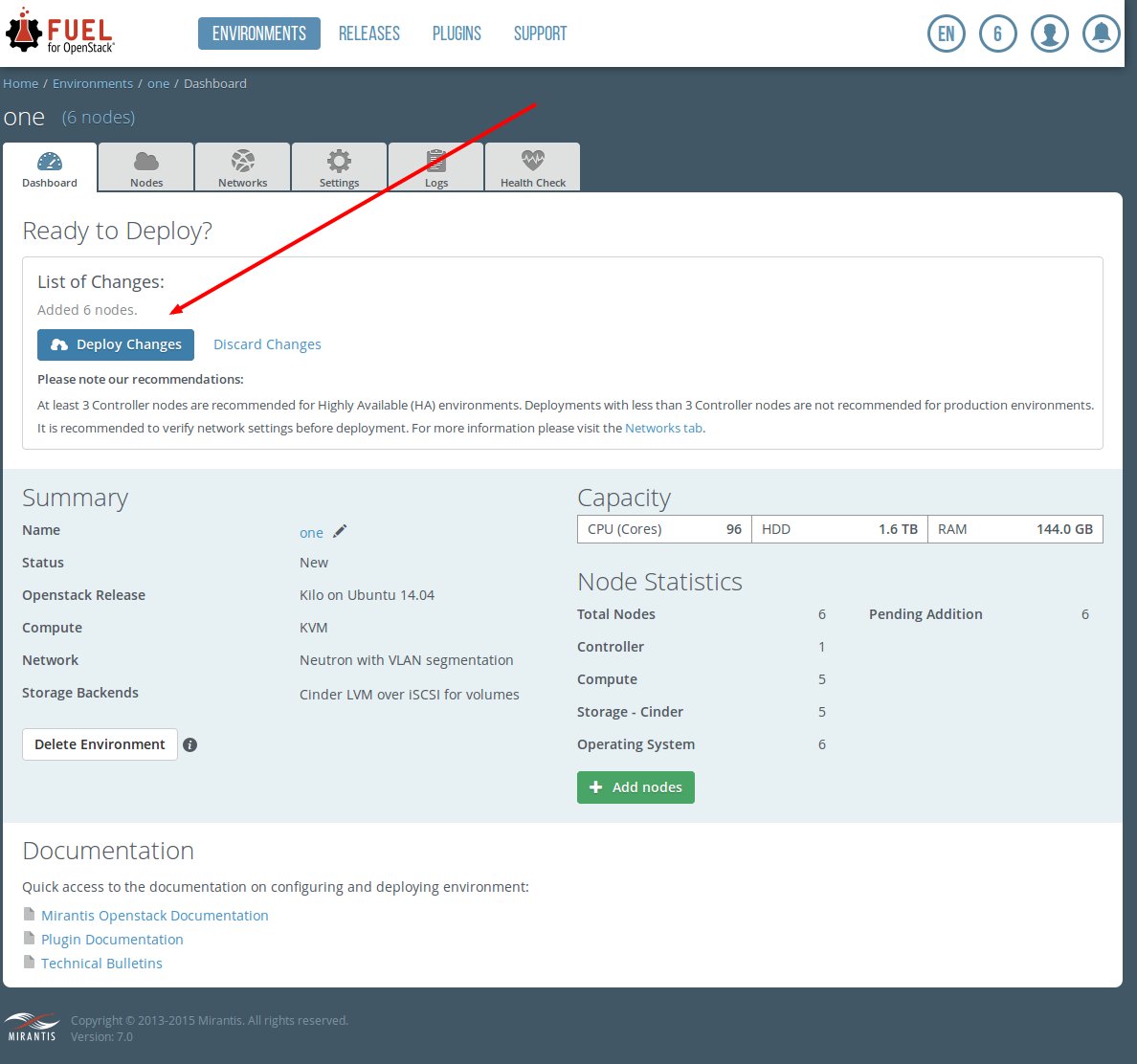
on Verification succeed, click on Save Setting click on the Dashboard tab
click on Deploy Changes
click on Deploy This install took 1 hr 17 minutes.
click on Proceed to Horizon
Tell me a story
I’ve had the privilege of being in an environment with lots of computers, customers, and home brew software. It is in this context, the term Technical Debit acquires a very deep and concise meaning to me. Openstack has a very noble goal, which is to provide an API that controls compute, storage and networking. It’s a very simple idea. The simplest ideas, when done right, are the most difficult. From this perspective, Openstack is by definition the compute, storage and networking version of Structured Query Language or SQL. SQL is the means in which we learned control data. When we didn’t have to deal with calculating, referencing, or translating data, we got better at managing data. Openstack is doing the same right now for compute, storage, and networking.
I’ve also had the privilege of contracting for many years. When entering a new environment, newbie have been the most successful when someone puts the effort in to introducing them to the ways of the tribe. I’ve since found out that the term tribal knowledge came from military personnel working with indigenous warring fractions. Business is the peace time equivalent of war. A reason Openstack is popular is because it lessons the Technical Debit burden for companies who view management of compute, storage, and networking as a non-core business. Companies that make it their core business to provide compute, storage, and networking services and solutions are now in a life and death proposition of competing with open source. It’s obvious from that perspective why all these big name vendors joined Openstack foundation. They and many new startups are jockeying for key positions in the value chain. This is Nash Equilibrium swirling in front of us right now. Applying the Model View Control pattern to view Openstack Marketplace is a great beer drinking topic, and for attracting women.
In the spirit of open source, I present the above article. A goal for me is to work on a cloud application without vendor lock in. I’ve installed and tried Devstack, RDO, Openstack Ansible, and Kolla. It’s time to see what a physical deployment looks like in comparison.
I had a Dell 1955 chassis with 7 blades. I wanted to redeploy that beast. The combination of needing 240V and space was a challenge. I was OK with fixing DHCP on request. 240V, and the 10 Gauge extension cord tapped in to the stove outlet or dryer outlet; snaking through the home seemed a bit too much. I’ve never met the man, but I bet Steve Jobs would have just done it. The next consideration was to use the same generation of hardware with separate boxes. I had one Dell 2950. I could scavenge stuff from the Dell 1955 chassis. The litmus test I used to determine obsolescence of computer hardware was for comparing the value of hardware verses the cost of electricity to keep it running for a year. Intuitively, we know that all operators have a similar threshold. This is where Nash is working against me here. All the scrap yards have been sending that stuff to metal recycle bins for a while now.
At the end of the first day, I had no success using this generation of hardware. I gave in around noon on the second day. It was apparent that Clovertown was not the path of least resistance. I would have to let go of some green backs and go to Nehalem. I already had twoR710. I bought one 3 years ago and one a few months ago. The cost difference is best measured in multipliers. I located a local suppler and decided to get 5 more. The goal was to get Openstack working sooner than later. I had planned for more hardware challenges by over-buying, and arranged a purchase the next day. The seller agreed to meet me at 7 pm at a convenience store. A cash deal took place in the parking lot on a Friday night. I’ve never done that before.
Saturday morning, I stacked the servers up in the spare bedroom. I placed a sign on the door, and now it is my server room. Placement of the nodes was towards the back wall. I left space all the way around the servers. I knew it was going to get hot in that room, also that it was prone to be a cabling mess. Years before, I was advised by a lawyer I had once hired who said, “if you can explain what you did to a judge, and he doesn’t get a red face, it’s probably OK to do it”. I had visions of standing before a judge and saying, “Yes, the house burnt down because of an electrical fire” , “No, I didn’t check the amperage usage”, and “Yes, I have a degree in engineering.” In my imagination, he would then proceed to say, “Guilty of Negligence! Next!” I drove to the nearest Home Depot to purchase an amp meter, feeling slightly amazed how much my project was costing me. This project was cutting into my beer budget. I consoled myself by thinking, “beer from the grocery store is just as good as the beer at a pub.” I hooked up the amp meter then turned on all the servers. I confirmed that the amperage draw was about 80% of the 15 amp breaker feeding that room. My imagination wandered back to my hypothetical court case where I’d say, “I have no reason to believe that 500 pounds of computers, all hooked up to one outlet was a fire hazard, Your Honor.” I started work on the Fuel server, which is Centos install. This installs itself very well by using Docker to host micro services. This is very cool in my opinion. I left the default 10.20.0.2 on eth0. I assumed it needed access to the Net, so I added a second IP address to the unused port of the fuel server and connected it to the Home Network. I gave that port a default gateway, and removed the default gateway from the other port. As suspected, it phoned home and got more stuff before it completed the install. Upon completion, there was a message on the console with defaults, showing the URL for admin screen, password and root password. Nice! No Google-ing for the details were necessary. This project was pretty much all hacking. I glanced at the docs. Something in the back of my mind told me that this was not what I wanted to read. This was going to be a project where, if all else fails, read the docs. After getting a few nodes to DHCP boot, I discovered the Network Validate button. Even after NAT Translating 10.20.0.0/24 was confirmed to work, it still failed the validation test. Yes, I did try a few install runs with a failed validation. I can confirm that they ended in failed installs. Fuel wanted the pubic IP address to have Internet Connectivity, duh. The first attempt was obvious. Re-use the Home Network for Public address. I chose a range of IP addresses that looked safe for the existing natives, turned off DHCP, then ran Validate Network, which checked out OK. Let it rip. All was well until the end. Everything just locked up on the network. Not sure what went wrong. A variation of that configuration should work. I decided not to pursue reuse of the Home Network as the Openstack Public network. My Home Network has users with expectations of using DHCP without Fuel making their laptop an Openstack node. Yes, for the readers who are paying attention, the Fuel network is different than a combined Public and Home Network. The above is funnier! An option for alternate configurations could be to use a node for one or more of the NAT translations, opposed to one of the Home NAT routers. However, Home NAT routers are the best option for Ghetto Stack. They’re cheap to buy, cheap to operate, and easy to configure. Other deployments will have large variations in existing network construction, but Ghetto Stack is not about building a production oriented network. At this point, it’s time to buy another NAT router. It’s Midnight on Sunday. Off to Walmart I went, and I found a decent router that I’d be OK with taking with me on my next contract gig. A quick check with Google showed it was $10 cheaper at Best Buy. Say it, and it will happen. Price match, Price match, Price match. I saved one more beer at a pub! Now we have to actually put some thought into networking. There is no getting around doing a custom network configuration. Fuel needed to be on VLAN 1. That wasn’t going to change. Home Network must have separate DHCP. We shouldn’t have two DHCP servers on one network. Competition in market place is good. DHCP Competition on one network segment is bad. Home Network was assigned to VLAN 2. The NAT router providing Public IP address for Openstack will be double NAT. Google it. Some people on the net have postings that say it’s a bad idea. To them I say, Ghetto stack. The Double NAT router will get its public IP address from Home Network via DHCP on VLAN 2. It will configured to to use the 127.16.0.0/24 range with no DHCP. To hook up the double NAT router, plug one of its private Ethernet ports into the switch on a port configured for VLAN 100. The Fuel Network, 10.20.0.0/24 will remain on NAT translated by the workstation. The only way this network can be effectively used by an administrator is to have the workstation plugged into all the networks. This fits with a minimal keep-it-simple solution. That is what a minimal fuel network looks like. An alternative would be to translate an entire class B space. Use a router to make different subnets that can be seen by each other. That is another project for another day.
The end result is the Network Diagram at the beginning of this post. On most recent runs, I removed the second Ethernet connection on the fuel host that is connected to the Home Network. This is the initial boot strap internet connection for the Fuel server before the rest of the network was created. Be sure that Fuel network has public translations. A completely default install of Fuel, and one IP range change for an environment within Fuel will let Fuel fully install Openstack. This install of Openstack is still not fully functional. That just means Openstack consulting and support will stay in demand for the foreseeable future. At first glance, this may seem really bad. This is no different than the early days of PC. It took many attempts at installing any operating system on a system. Sometimes it took driver downloads or even parts replaced with different brands. This is the normal open systems cost of technical debit shared with whole community. I’m reminded of a buddy who figured out that his permutation of hardware and software worked only if he booted his PC with the CD Rom in the open position, and closed it during the boot process. I never did ask how long he took to figure that out.